Sharing hearing data without sharing patients
What is the problem?
Around 1.5 billion people worldwide live with hearing loss, making it one of the biggest causes of years spent in poor health. To improve how we detect, diagnose, and treat hearing problems, researchers and engineers need to study large collections of hearing test results. The trouble is that this kind of data is sensitive medical information, protected by laws like GDPR. Even though a hearing test might seem less private than other health records, the pattern of someone's results can hint at things like their job history, exposure to certain medicines, or inherited conditions.
This means that hospitals are often unable to share data, sharing agreements take years to put in place, and rare hearing conditions are barely represented in any single dataset. The result is slower progress in hearing healthcare. Particularly for the artificial intelligence (AI) tools that increasingly help with diagnosis, hearing aid fitting, and screening.
What did we do?
We tested two ways of creating "synthetic" hearing test data: realistic, computer-generated profiles that look and behave like real patient data but don't belong to any real person. Sharing this kind of data is much safer because there is no individual to identify.
We compared two approaches:
- A simple statistical method that learns the shape of the data and samples new examples from it.
- A modern AI method that learns the underlying patterns in hearing test results and uses them to generate new, plausible profiles.
We trained both methods on a large public dataset of hearing tests from 29,714 people in the United States.
Figure 1 shows an example of what the AI's output looks like alongside a real hearing test from the same dataset.
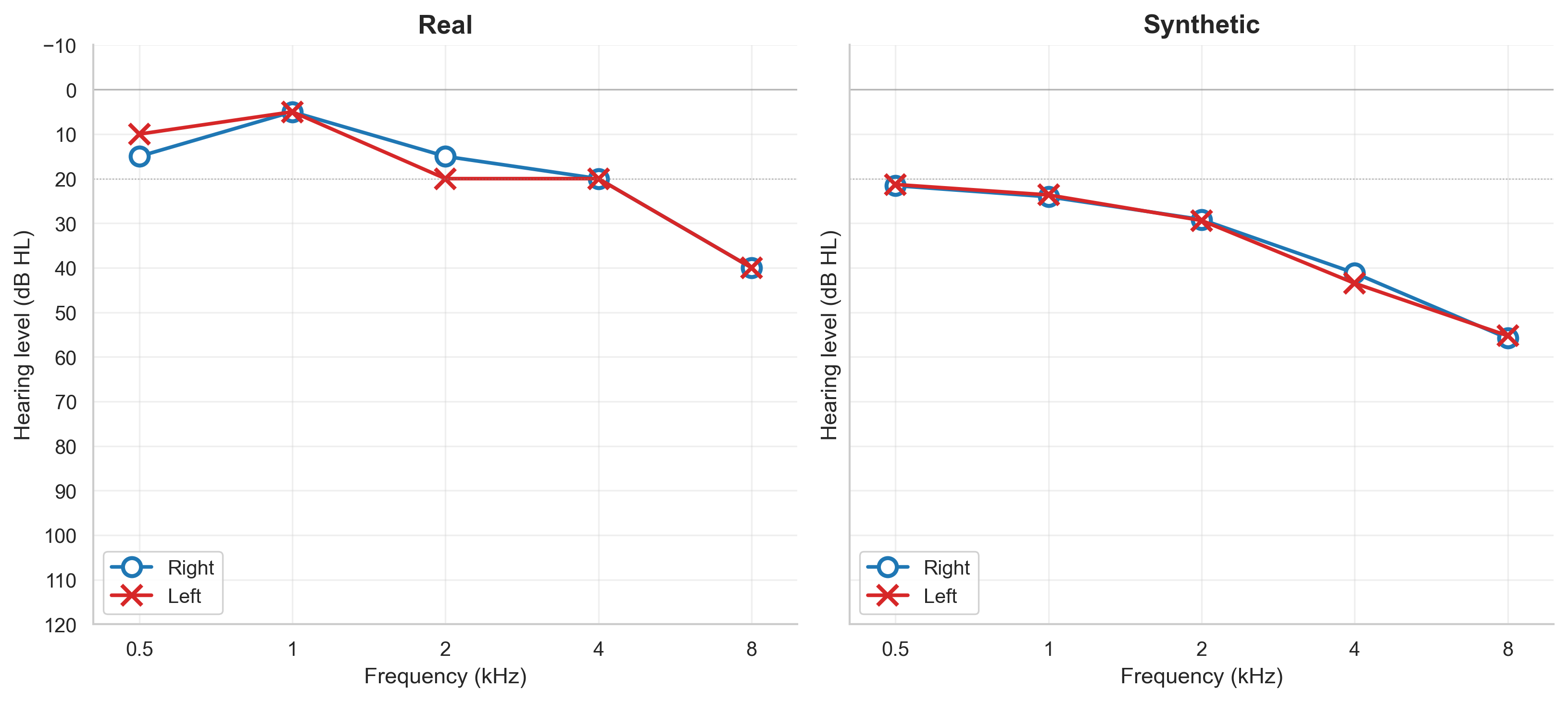
How did we test it?
We checked the synthetic data in four ways:
- Could AI learn from it? We trained hearing-loss prediction models on the synthetic data and tested them on real data. The AI-generated data produced models that worked nearly as well as those trained on real data — about 86% as accurate.
- Was it statistically realistic? Across every hearing test frequency, the synthetic data matched real data to within less than 1 decibel — a difference too small to matter clinically.
- Did it convince the experts? Two audiologists reviewed 85 patient profiles without knowing which were real and which were synthetic. They rated 97% of the AI profiles as clinically plausible, compared with just 13% for the simple method. Both audiologists independently judged the AI profiles as more realistic than the real ones.
- Was it private? We ran standard privacy attacks to see if anyone could trace synthetic profiles back to real patients. Both methods passed.
What difference does this make?
This work gives the hearing health community a tested, validated way to share hearing data without putting patient privacy at risk. The synthetic data we generated can be used to:
- train AI tools for hearing-loss prediction without needing access to real patient records;
- develop and benchmark new hearing aid fitting algorithms;
- give audiology and ENT trainees realistic case examples for learning;
- enable hospitals and universities in different countries to collaborate without long data-sharing agreements.
More broadly, the same approach can be adapted for other types of structured health data, making this a useful blueprint well beyond audiology. By lowering the privacy barrier to data sharing, we hope to speed up the development of better, fairer hearing healthcare for everyone.